АЛГОРИТМ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ ДЛЯ САНКЦИОНИРОВАНИЯ ДОСТУПА К ИНФОРМАЦИИ
Научная статья
Чернецова Е.А.1, *, Шишкин А.Д.2
1 ORCID: 0000–0001–5805–3111;
2 ORCID: 0000–0003–1992–5663;
1, 2 Российский Государственный Гидрометеорологический Университет, Санкт-Петербург, Россия
* Корреспондирующий автор (chernetsova[at]list.ru)
Аннотация
Представлен алгоритм для автоматизации процесса идентификации личности по голосу. Проводится обзор существующих методов решения поставленной задачи. Реализуется метод, основанный на применении модели гауссовых смесей, который позволяет отличать голоса людей с высочайшей точностью, поскольку компоненты гауссовых смесей могут моделировать особенности голоса, индивидуальные для каждого человека. Приводятся результаты тестирования реализованного алгоритма, делается вывод о применимости модели гауссовых смесей для решения задачи идентификации личности по голосу.
Ключевые слова: алгоритм, идентификация, голос, модель, гауссовская смесь.
ALGORITHM FOR PERSONAL IDENTIFICATION BASED ON VOICE FOR INFORMATION ACCESS AUTHORIZATION
Research article
Chernetsova E.A.1, *, Shishkin A.D.2
1 ORCID: 0000–0001–5805–3111;
2 ORCID: 0000–0003–1992–5663;
1, 2 Russian State Hydrometeorological University, Saint Petersburg, Russia
* Corresponding author (chernetsova[at]list.ru)
Abstract
The authors present the algorithm for automating the personal identification process based on a voice. A review of existing methods for solving the problem is presented as well. The method based on the use of a Gaussian mixture model is implemented, it allows to distinguish the voices of people with the highest accuracy since the components of Gaussian mixtures can simulate voice characteristics that are individual for each person. The results of testing the implemented algorithm are given, the conclusion is drawn about the applicability of the Gaussian mixture model for solving the problem of identification by voice.
Keywords: algorithm, identification, voice, model, Gaussian mixture.
У любого человека есть свои особые вокальные характеристики, определяемые индивидуальной структурой его голосового аппарата. Прислушиваясь к разговору, человек может на уровне подсознания идентифицировать голоса любых других людей, однако разработка автоматического различителя речи сопряжена со значительными трудностями [1].
Задача распознавания человека по голосу состоит в выделении из входного аудиопотока человеческой речи, ее классификации и распознавания. При этом обычно решаются две подзадачи: распознавание говорящего и проверка. Для решения этих подзадач можно определить метод расчета степени сходства выборки с опорными сигналами. Степень сходства опорной и тестовой выборок можно рассчитать с использованием определенной меры расстояния или с использованием вероятностных критериев [2]. Алгоритм идентификации говорящего можно также определить как текстозависимый и текстонезависимый. Если алгоритм идентификации речи зависит от текста, то в нем можно использовать как фиксированные заранее фразы, так и фразы, которые генерируются системой распознавания. Текстонезависимые системы необходимы для обработки произвольной речи [3].
В данной статье обсуждается проблема автоматической идентификации личности по ее вокальным характеристикам и реализуется алгоритм, который решает проблему текстозависимой идентификации.
Методы моделирования говорящего человека прошли большой путь от выполнения усреднения векторов признаков до осуществления сложных порождающих и дискриминационных моделей [4]. Концепция порождающих моделей включает в себя моделирование данных, применяемых при обучении, например, путем оценивания функции плотности вероятности (для модели гауссовых смесей). Дискриминационные модели призваны разграничивать отдельные классы (например, при реализации метода опорных векторов) [5].
В настоящее время широко распространены следующие способы для моделирования говорящего человека [6]:
- для класса текстозависимых систем – динамическое преобразование времени (Dynamic Time Warping; DTW) и скрытые марковские модели (Hidden Markov Model; HMM);
- для класса текстонезависимых систем – векторное квантование (Vector Quantification; VQ), модели гауссовой модели смеси (GMM) и метод опорных векторв (опорная векторная машина (SVM).
Dynamic Time Warping (DTW) – алгоритм динамического преобразования шкалы времени, метод динамического программирования, позволяющий находить расстояние между двумя временными рядами. Как правило, такие последовательности имеют разную длину, поэтому приходится производить измерения с различными скоростями. Основное преимущество данного алгоритма – это простота реализации. Хотя этот алгоритм с успехом используется в различных приложениях, иногда он дает неверные результаты. Алгоритм пытается исправить несогласованность оси x путем преобразования оси y, что может вызвать выравнивание, в котором одна точка исходного временного ряда связана с довольно большим массивом точек другого временного ряда [7]. Другая проблема при реализации данного алгоритма заключается в том, что ему трудно обнаружить выравнивание двух строк в связи с тем, что некоторое значение ( которое может иметь вид пика, впадины, плато, максимума или минимума функции) одного ряда расположится несколько выше или несколько ниже соответствующей точки в другом ряду [8].
Если для решения задачи распознавания нескольких классов применяется метод опорных векторов, то часто можно использовать стратегию «один против другого». Это требует построения q-классификаторов, при этом каждый классификатор можно обучить отличию одного конкретного класса от других. При решении задачи идентификации объект будет определен как принадлежащий к классу, классификатор которого дает максимальное значение разделяющей функции f(x). Метод опорных векторов предполагает высокую точность классификации, имеет теоретическое обоснование, позволяет применение различных подходов к классификации в соответствии с выбором основной функции. Среди недостатков метода нужно отметить необходимость выбора ядра, а также достаточно большое время, необходимое для произведения процедуры обучения алгоритма для решения задачи многоклассового распознавания [9].
Модели гауссовых смесей могут быть применимы не только для моделирования характеристик голоса говорящего, но и для записи сигнала голоса и окружающей среды. Каждый из компонентов модели отражает некоторые общие особенности голоса, но индивидуальные при их воспроизведении каждым говорящим. Модели гауссовых смесей доказали свою эффективность , так как обладают высокой точностью распознавания. Именно поэтому этот подход может быть успешно использован для решения проблемы идентификации текстонезависимого говорящего [10].
Расчет взвешенной суммы М компонент, представляющих модель гауссовых смесей, производится по формуле [11]
![]() (1)
(1)
где ![]() – D-мерный вектор случайных величин, pi, 1≤ i ≤ M – веса компонентов модели,
– D-мерный вектор случайных величин, pi, 1≤ i ≤ M – веса компонентов модели, ![]() ,1≤ i≤ M – функции плотности распределения составляющих модели:
,1≤ i≤ M – функции плотности распределения составляющих модели:
![]() (2)
(2)
где ![]() – вектор математического ожидания и ∑i – ковариационная матрица. Веса смеси должны удовлетворять условию:
– вектор математического ожидания и ∑i – ковариационная матрица. Веса смеси должны удовлетворять условию:
![]() (3)
(3)
Модель гауссовой смеси целиком определяется с использованием векторов математического ожидания, ковариационных матриц и весов смесей для каждой из компонентов модели:
![]() (4)
(4)
При использовании метода каждый говорящий человек может быть представлен своей моделью гауссовской смеси.
Чтобы построить систему автоматической идентификации личности по голосу с использованием гауссовых смесей необходимо решить следующие подзадачи:
- Извлечь и обработать признаки входного речевого сигнала;
- Разработать алгоритм инициализации и оценки параметров модели;
- Определить число компонентов модели гауссовых смесей.
Сначала выполняется аналогово-цифровое преобразование звукового сигнала. При дискретизации сигнал разбивается на отдельные значения квантованной амплитуды через некоторые временные интервалы.
Вся запись сигнала просматривается окнами заранее заданной длительности, которые перекрываются. Рекомендуется выбирать длительность временного окна в пределах 20-30 мс. В данной работе для упрощения расчетов длительность каждого окна была выбрана равной 25 мс.
Затем оцифрованный сигнал просматривается небольшими фрагментами (кадрами), которые характерны для отдельных вокальных компонентов речевого сигнала и для которых предполагается, что сигнал сохраняет постоянными свои свойства на данном промежутке времени. Далее происходит выбор функции окна. Функция временного окна должна принимать значение, не равное нулю, внутри некоторого временного отрезка, а за его пределами должна быть равна нулю. Затем функция окна последовательно налагается на фреймы сигнала, и из речевого кадра происходит извлечение информации. Извлечение этой информации происходит с помощью перемножения значения сигнала x[t], взятого в момент времени t со значением оконной функции w[t], взятой в момент времени t:
![]() (5)
(5)
Характеристиками оконной функции являются следующие параметры: ширина (в миллисекундах), смещение (число миллисекунд между границами последовательных окон) и форма. В данной работе применяется окно Хэмминга с шириной L = 30мс и смещением 10 мс.:
![]() (6)
(6)
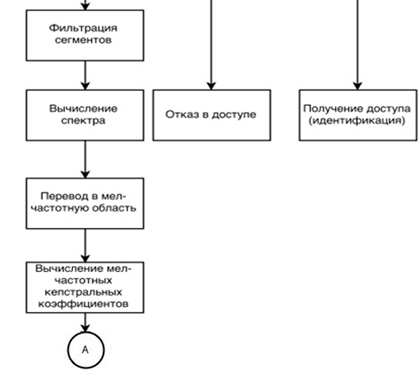
После фильтрации каждого сегмента получаем полный сигнал, в котором отсутствуют шумы, помехи и прочие искажения, могущие мешать правильному распознаванию говорящего.
Далее необходимо извлечь из сигнала, полученного на предыдущих этапах алгоритма, информацию о спектральных составляющих, для чего используется дискретное преобразование Фурье. На вход вычислителя подается сигнал, разбитый на кадры, а на выходе вычислителя для каждого из T частотных диапазонов получаем комплексное число X[k], которое является амплитудой и фазой исходного сигнала. X[k] вычисляется по формуле:
![]() (7)
(7)
где k = 0,…,N-1.
Затем необходимо перейти от величины частоты звука f к значению высоты (мел). Сначала нужно расположить полученный спектр на мел-шкале. Эту операцию осуществляем по формуле
![]() (8)
(8)
Данная операция нужна для моделирования того, что человеческий слух имеет неодинаковую чувствительность в различных частотных диапазонах.
Затем необходимо сформировать треугольные фильтры, служащие для накопления значения энергии в каждом из частотных диапазонов (10 фильтров распределяются линейно ниже 1000Hz, а остальные – логарифмически выше 1000Hz) и взять логарифм каждого полученного значения мела. Использование логарифма необходимо для того, чтобы различия в способах подачи входного сигнала меньше влияли на оценки индивидуальных признаков речи.
Далее переводим полученные значения в шкалу с частотами. На следующем шаге алгоритма вычисляется кепстр сигнала. Это преобразование позволяет отделить источник волны звука от фильтра, свойства которого позволяют генерировать соответствующий звук при прохождении волны, имеющей частоту основного тона речи по голосовому каналу. При этом фильтр содержит большую часть полезной информации.
Каждый сегмент сигнала может быть описан с помощью 12 мел-частотных кепстральных коэффициентов. Для их нахождения используем формулу
![]() (9)
(9)
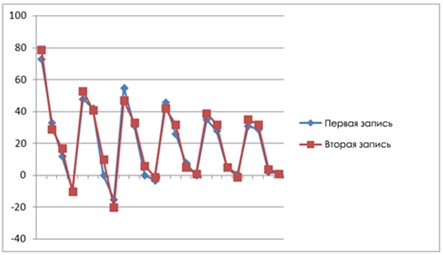
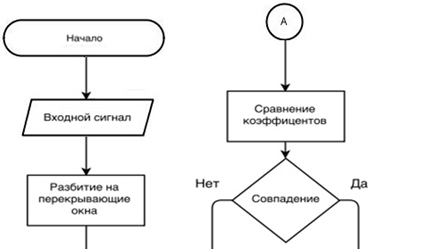
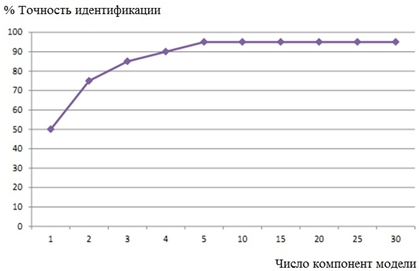
где 0≤ n На рисунке 1 представлен график зависимости мел-частотных кепстральных коэффициентов от времени для двух кадров речевого сигнала двух различных дикторов, которые произносили одинаковую речевую фразу. На графике можно видеть, что коэффициенты записи различаются для разных говорящих. Зависимость мел-частотных кепстральных коэффициентов от времени для двух различных записей речи одного и того же диктора представлены на рисунке 2. Из графика рисунка 2 можно видеть небольшую разницу между мел-частотными кепстральными коэффициентами. После того, как рассчитаны все коэффициенты, сигнал записи должен пройти процедуру сравнения с эталонным сигналом, хранящимся в базе данных. Критерием совпадения этих сигналов будет являться мера расстояния Евклида. На рисунке 3 представлена полная блок-схема алгоритма, на основе которой разработана программа для идентификации личности по ее вокальным данным. Рис. 1 – Зависимость мел-частотных кепстральных коэффициентов записей речи двух различных дикторов от времени в первых двух фреймах речевого сигнала Рис. 2 – Зависимость мел-частотных кепстральных коэффициентов записей речи одного и того же человека от времени в первых двух фреймах речевого сигнала Чтобы инициализировать начальные параметры модели, в данной работе был использован алгоритм кластерного анализа для векторов признаков речевого сигнала. В качестве алгоритма кластеризации был выбран алгоритм K-means++, в котором в качестве меры искажения используется евклидово расстояние [12]. Рис. 3 – Блок-схема алгоритма автоматизации процесса идентификации диктора по голосу Алгоритм K-means++ представляет собой модификацию алгоритма K-means. В данном алгоритме производится случайный выбор центра первого кластера, а затем каждый последующий центр может быть выбран из оставшихся точек данных с вероятностью, пропорциональной квадрату расстояния до ближайшего существующего центра кластера. После этого происходит выполнение стандартного алгоритма K-means. Преимуществом такого подходя является большое уменьшение погрешности конечного результата. Для тестирования разработанного алгоритма было разработано программное средство на языке С++. Были отобраны голосовые сигналы двадцати человек. Записи речи производились в моно режиме с помощью встроенного в компьютер микрофона, имеющего частоту дискретизации 16 кГц и разрядность АЦП, равную 16 бит. Длительность речевого сигнала составляла 50 секунд, а длительность сигнала-теста – 15 секунд. Проверка работоспособности алгоритма производилась при различном числе компонент модели гауссовых смесей. На рисунке 4 изображена зависимость числа правильно идентифицированных дикторов (в %) от числа компонент модели гауссовых смесей. Рис. 4 – Зависимость числа правильно идентифицированных дикторов (в %) от числа компонент модели гауссовых смесей Результаты разработки алгоритма автоматической идентификации личности по голосу для санкционирования доступа к информации, полученные в данной работе, позволяют сделать следующие выводы: Не указан. None declared. Список литературы / References Список литературы на английском языке / References in English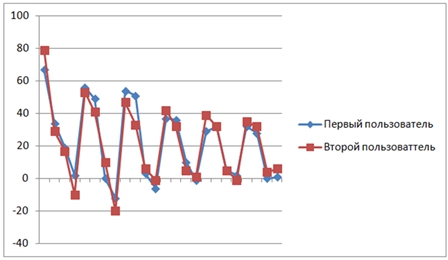
Конфликт интересов
Conflict of Interest